

Interviewing for a Software Engineering position is unlike the interview process for most other professions. Some parts are similar, in that you will likely be questioned about your previous employment and education, and asked competency questions to test your situational judgement and experiences. However, the main attribute interviewers are looking for in the process is your programming ability. You will need to demonstrate that you can think quickly and solve technical or logical problems presented to you. This often involves talking through code on the phone or a video call, or writing up a solution on a whiteboard. You can usually code in any popular programming language such as Java or C++. In order to help you with your software engineering interview, we will be using the Python programming language, as it is easy to read, and has minimal syntax, making it ideal for interview situations.
During these technical stages of the software engineering interviews, it is almost guaranteed that you will be asked questions about data structures such as stacks, trees, and hash maps. You may also be asked about algorithms, which are often ideally solved by using a particular data structure. Here we will be looking at one such data structure – linked lists. What are they, why are they used, and how are they implemented?
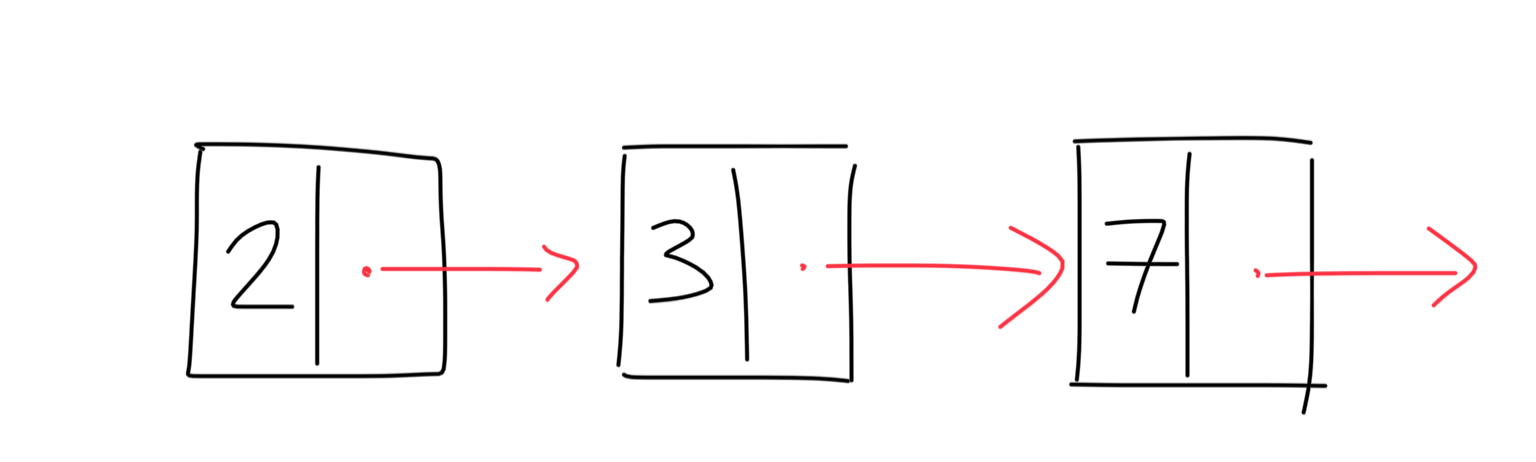
So let’s start with the basics. What exactly is a linked list? A linked list is a chain of connected nodes, and nodes are objects consisting of a value and a pointer to another node. The diagram below helps visualise this concept.
Defining Classes
To implement a linked list, the first thing to do is to create a Node class, which will hold the data of the node and a pointer to the next node in the chain.
class Node:
def __init__(self, data=None, next=None):
self.data = data
self.next = next
As the linked list itself is just a chain of nodes, to store the list we essentially just need a reference to the first node. Our LinkedList class is created below to store the head of the list.
class LinkedList:
def __init__(self):
self.head = None
Printing a Linked List
One of the most basic functions required of our linked list is the ability to print it. Printing the values of a linked list will be particularly useful when testing that other operations are performing as expected. An iterative method can be used to traverse through each node of the list and print out their values.
def print_list(self):
node = self.head
while node != None:
print(node.data)
node = node.next
Inserting Nodes
Two further key functions are inserting and deleting a node to and from the linked list. Let’s start with inserting a node. A node could be inserted at the head of the list, at the tail of the list, or somewhere inbetween. The simplest of these options is at the head of the list.
def insert_at_head(self, data):
self.head = Node(data, self.head)
In this single line we create a new Node object with the data passed in, and it points to the current head node. Our new node is then assigned as the head of the linked list. So our list is now headed by the new node, which points to the old head, where the list continues as previous.
Inserting a node at the tail of the list requires a little more effort.
def insert_at_tail(self, data):
# if empty list, insert as head node
if self.head==None:
self.head = Node(data, None)
else:
current_node = self.head
while current_node.next != None:
current_node = current_node.next
current_node.next = Node(data, None)
If the list is currently empty, then the tail and head are the same node, so we insert our one node as the head of the list. If the list is not empty, we iterate through the nodes until we reach the current tail. We then point this tail node to our new node, therefore appending it onto the end of the list.
We can also insert a node at a specific index (a numeric position in the list). To do this, we again first check for an empty list, in which case we insert as the head node. If the list is not empty, we want to iterate through the nodes in the list until we reach the desired index position. If we reach the end of the list before our index, then the position is out of range and no nodes are inserted. If we do reach the desired index in the linked list, we set the node at the penultimate index position to point to our new node, and set our new node to point to the previous node’s pointer.
def insert_at_index(self, data, index):
# if empty list, insert as head node
if self.head==None:
self.head = Node(data, None)
return
i=0
current_node = self.head
while i<index:
# if index out of range, do not insert
if current_node.next==None:
return False
current_node = current_node.next
i+=1
current_node.next = Node(current_node.data, current_node.next)
current_node.data = data
Deleting Nodes
For deleting a node at a specific index, the approach is similar to inserting. We again iterate through the linked list until our desired index position, but this time as well as keeping track of the current node, we also need to keep track of the previous node. This is because once our desired index position is reached, we set the previous node to point to the current node’s pointer. This essentially makes the chain skip over the current node, and it is deleted as nothing references it any more.
def delete_at_index(self, index):
# if index negative, do not delete
if index<0:
return False
i=0
prev_node = None
current_node = self.head
while i<index:
# if index out of range, do not delete
if current_node.next==None:
return False
prev_node = current_node
current_node = current_node.next
i+=1
if prev_node==None:
self.head = current_node.next
else:
prev_node.next = current_node.next
Testing
Below are some testing examples to make sure our linked list is performing as expected. Whenever you are coding up data structures, be sure to think about edge cases such as non-positive integers and values out of range.
list1 = LinkedList()
print(“Empty list:”)
list1.print_list()
print(“Node inserted at head:”)
list1.insert_at_head(‘hello’)
list1.print_list()
print(“Node inserted at head:”)
list1.insert_at_head(5)
list1.print_list()
print(“Node inserted at tail:”)
list1.insert_at_tail(‘end’)
list1.print_list()
print(“Node inserted at index 2:”)
list1.insert_at_index(11,2)
list1.print_list()
print(“Node inserted at index 0:”)
list1.insert_at_index(‘start’,0)
list1.print_list()
print(“Node inserted out of range:”)
list1.insert_at_index(‘Should not see this’,100)
list1.print_list()
print(“Node deleted at index 1:”)
list1.delete_at_index(1)
list1.print_list()
Why Linked Lists?
Now that we know the basics of linked lists, its worth considering why they would be used. The main advantage is the fact that they are a dynamic data structure, where memory is only allocated as needed, unlike arrays which have a predetermined size. They are also useful for implementing further data structures such as stacks and queues, where access to the head and tail nodes is valuable.
One disadvantage to using linked lists is that you use extra memory by storing both the data and a pointer for each node. To access a particular node in the list can require a full traversal, which is another downside in terms of time complexity.
In software engineering interviews, the topic of time complexity will often come up as an important consideration when evaluating your code. Linked lists have varied time complexities for insertion and deletion. Inserting at the head of the list is only O(1), but traversing a list takes O(n) time, and is required for inserting or deleting at a particular index, a node lookup, and more complicated operations.
Sample Interview Question
An example of a question you may be asked in an interview is how to reverse a linked list. Try to solve this on your own first, then check with our solution below to see if you used the same approach.
def reverse(self, node):
if node==None or node.next == None:
self.head = node
return
self.reverse(node.next)
node.next.next = node
node.next = None
There are different ways to approach this kind of question – so don’t worry if yours is different! Here we went for a recursive solution. We are passing in a node, which in the initial function call will be the head of the list. Then we have the base case, where we check whether we have reached the end of the list (the last node), in which case set the head node as the node passed in – this is essentially ‘reversing’ a single node.
If we have not yet reached the base case, we then have our recursive call, which reverses the list starting from the next node. The final two lines are the actual reverse, where we set our node’s next node to point back to our node, and our node to point to None, as we are at the end of the list.
What Next
Some ideas to think about for extending your knowledge of linked lists:
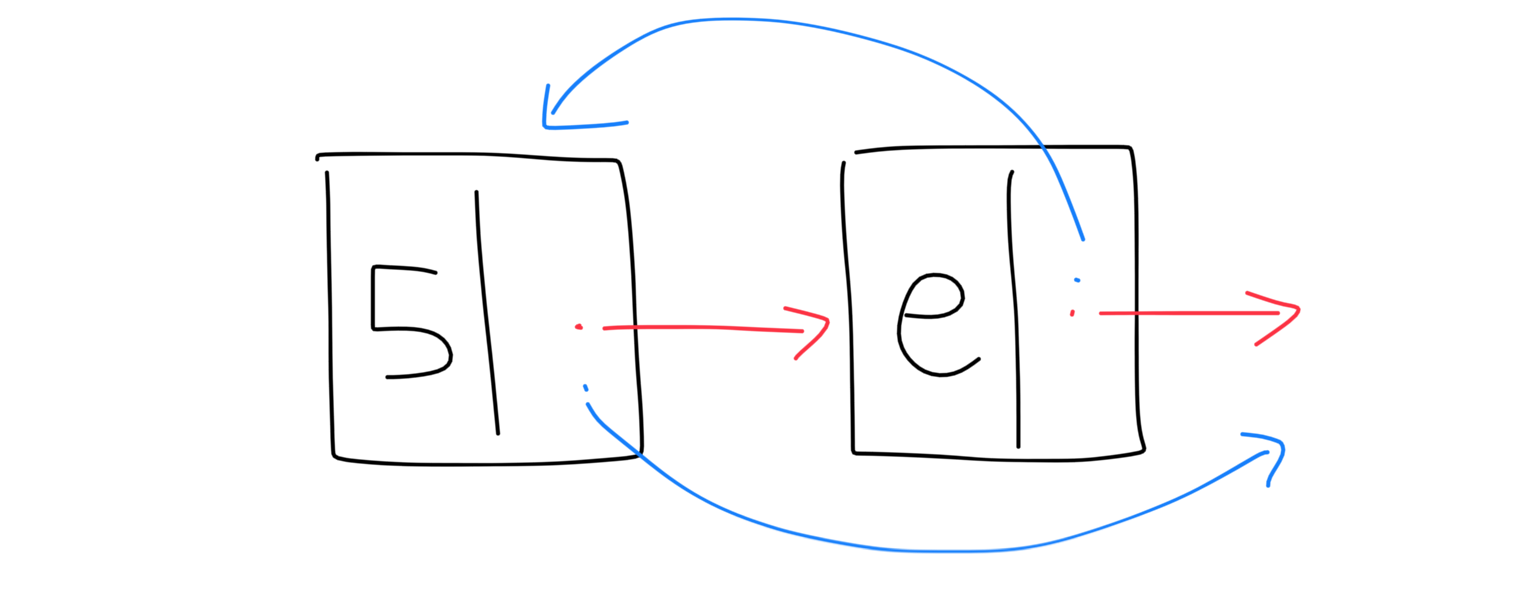
- So far we have been working with a linked list that is only connected in one direction – this is known as a singly linked list. There also exists a data structure called doubly linked lists, where each node has pointers to both the next node and the previous node. What would you need to add to implement this functionality?
- It might be useful to store other attributes of the linked list in the class, such as a pointer to the tail node, or a counter for the length. How could these aid our functions?
- If we wanted to lookup a particular node in the linked list, what would be the best-case and worst-case time complexity for this operation?
Check back soon for another post on data structures and algorithms which may be the key to success at your next Software Engineering interview!
