

Introduction
In this tutorial we will be looking into accelerated cloud computing – what it is, why we might want to use it, and how to set it up. All code for this tutorial is provided, but we will assume some familiarity with basic shell commands.
Cloud computing in general refers to using compute power, storage, applications and/or resources through a remote platform, which you can access on-demand and scale to your personal requirements. Using cloud computing service providers means we don’t need to deal with this kind of infrastructure or maintenance ourselves, and can instead focus on how to best utilise the extra compute capacity for our needs. There are certain tasks where accelerated computing, using GPUs rather than CPUs, is a more efficient approach in terms of time and cost. This is often the case with tasks that are massively parallel, meaning the work can be distributed in parts to execute simultaneously. We will be setting up our GPU for one example of such a task: deep learning.
There are a number of different cloud service providers, including Microsoft, Google, Oracle, and IBM. We will be using the market-leader, Amazon, to set up our GPU with Amazon Web Services (AWS).
Account Setup
To sign up for an account with AWS, we need to head to this link and fill in all our details. We will then arrive at the AWS Console – the dashboard showing all available services and tools.
Before we can get going with our GPU setup, we first need to request a service limit increase. AWS accounts are initialised with a limit of 0 instances for certain configurations, and one of those is the p2.xlarge instance which we require. So, from the main dashboard click on EC2 instances and then limits:
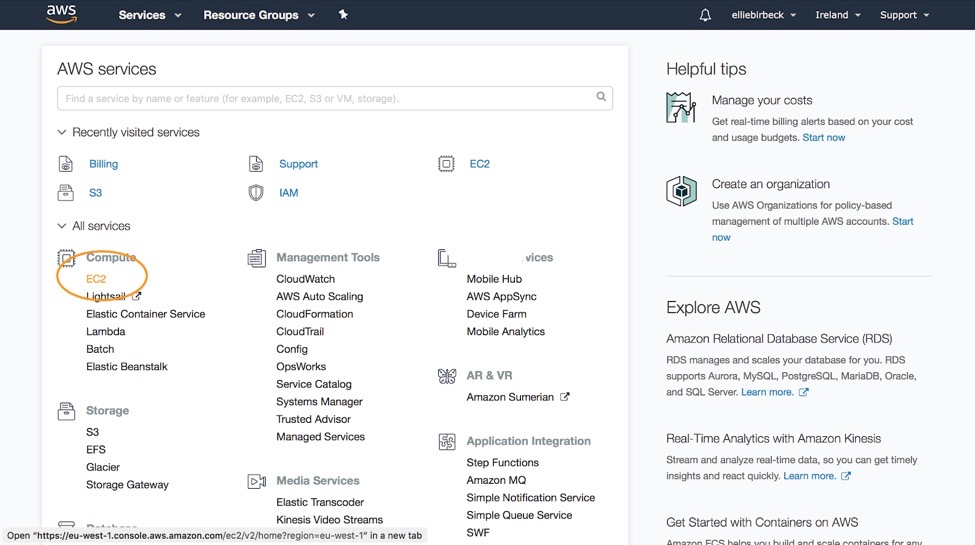
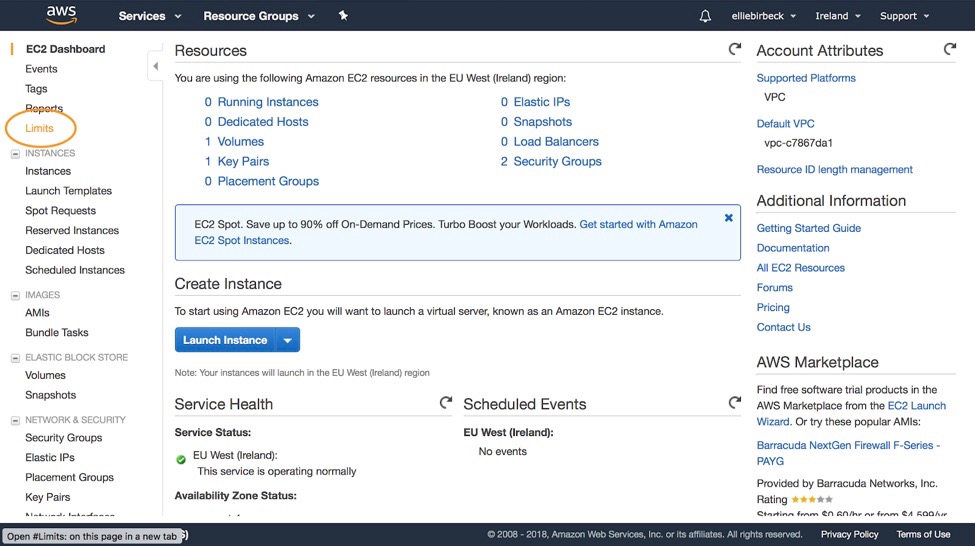
On this page you need to scroll down until you reach the ‘Running On-Demand p2.xlarge instances’ row of the table. Here you should click ‘Request limit increase’.
If you do not see p2.xlarge as an option – don’t worry. There are many different server farms used by Amazon all around the globe, and not all of them support GPUs. You have to select a region to associate your account with, which is usually the closest one to your personal location. The list below states which regions currently support GPU instances, so change your region settings (at the top right of the screen, next to your account name) to one of the below locations. Selecting the closest one to your actual location will reduce latency.
- US East (Ohio)
- US East (N. Virginia)
- US West (Oregon)
- Asia Pacific (Seoul)
- Asia Pacific (Sydney)
- Asia Pacific (Tokyo)
- Asia Pacific (Singapore)
- Asia Pacific (Mumbai)
- China (Beijing)
- Europe (Ireland)
- Europe (Frankfurt)
Once we have clicked ‘Request Limit Increase’ for the p2.xlarge instance, we can fill out the form details as follows:
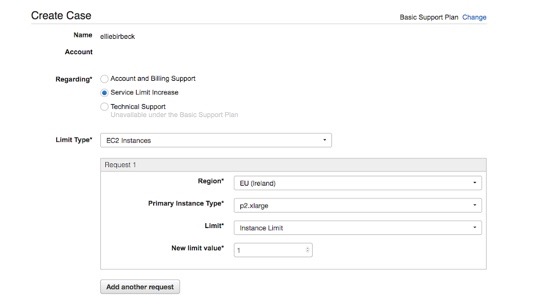
Any reasonable example can be entered for the use-case, such as ‘deep learning’. Once submitted, the response time for our request can vary, but we will receive an email update once it has been accepted.
Security Keys
We also need to configure some security settings for our account, so head back to the main dashboard by clicking on the AWS logo at the top left.
From the main dashboard, scroll down to the subsection titled ‘Security, Identity, & Compliance’ and in this column click on ‘IAM’ which stands for ‘Identity and Access Management’. Then on the left hand side click on ‘Users’, and then the blue ‘Add User’ button.
Here we create a username for ourselves, and select to give both programmatic access and AWS management console access to this user. We can choose the password details depending on personal preference.
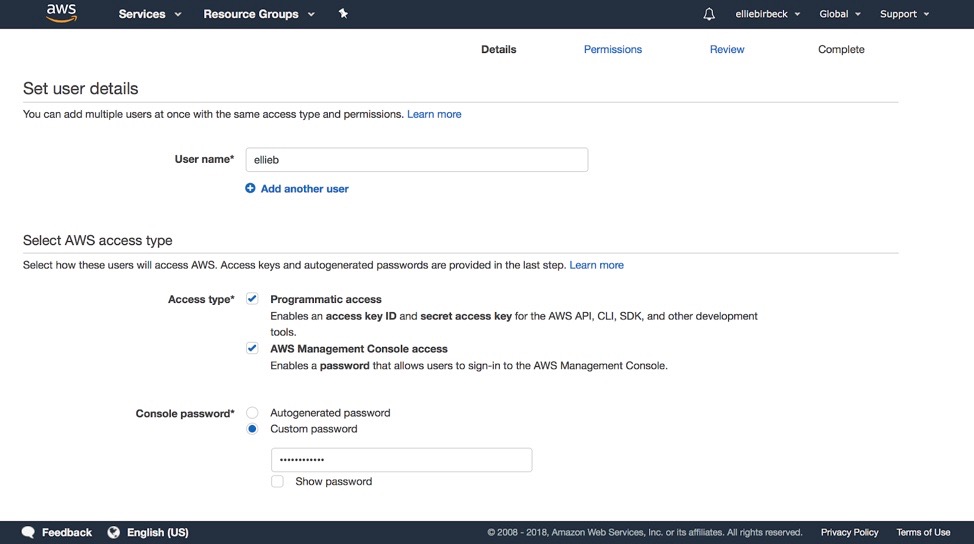
To set the permissions for this user, we want to attach existing policies directly. Here we select ‘Administrator Access’ which should be the first row of the table, and continue to the final review stage.
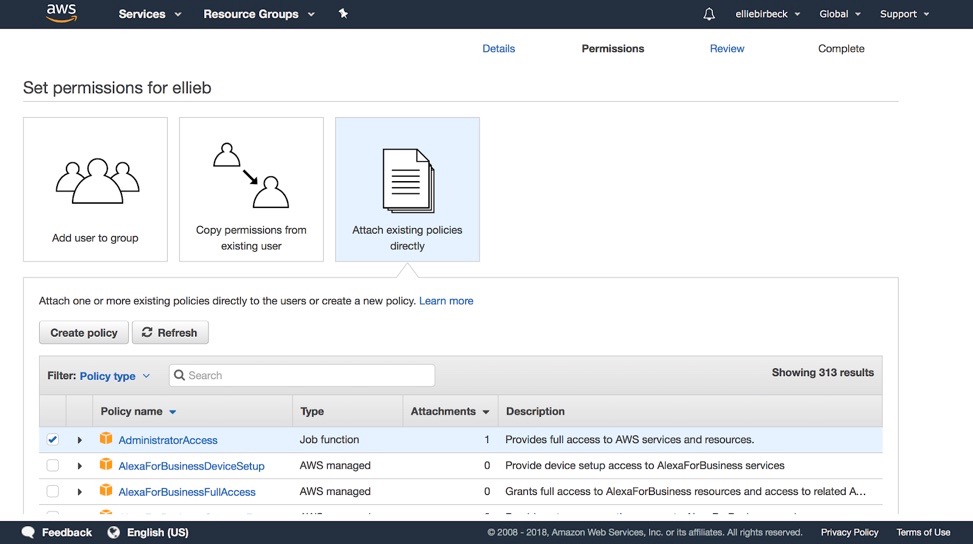
After confirming the details, our administrator user is now created. Two key pieces of information will be displayed at this stage: the Access Key ID and the Secret Access Key. You should save both of these for later steps in our setup.
Command Line Interface
So far, we have been exploring what is known as the AWS Console – the web-based user interface displayed as a dashboard. We can also access AWS through their Command Line Interface (CLI). The AWS CLI is Python-based, so it can be installed using the package manager pip. Let’s open up our terminal to check whether pip is installed (and if not, install it here), and then execute the following command:
pip install awscli
Next we need to configure the CLI with the correct settings for our account:
aws configure
The CLI will ask us for our Access Key ID (which you should have noted down earlier), along with the region name, and output format. For region name, choose the one corresponding to your selected region earlier (ours is ‘eu-west-1a’ for Ireland), and for output format use ‘text’.
AWS Access Key ID [********************]: your-access-key-ID-here AWS Secret Access Key [********************]: your-secret-access-key-here Default region name [eu-west-1a]: eu-west-1a Default output format [text]: text
Our CLI is now configured to the correct user settings.
The amount of tools and services available through AWS is vast, so naturally the CLI has many possible commands. A full reference point for navigating your way around is available here, but we will be mostly using the Console for our setup.
Elastic Compute Cloud
The main AWS product that we will be using in this tutorial is known as the Elastic Compute Cloud (or EC2). EC2 is a service that allows us to configure and use virtual servers in the cloud, extending our compute capacity beyond our own personal machines.
Each instance we choose to set up can be configured in a number of different ways, and there is also the option to use Amazon Machine Images (AMIs) to speed this process up. AMIs are pre-configured setups with popular libraries, frameworks, drivers, and other options included for us.
To set up our first instance, head to the EC2 dashboard and click the large blue ‘Launch instance’ button. This takes us to the first stage of setting up our instance – selecting the AMI. Here you could choose to set up with your own AMI using the ‘My AMIs’ option on the left hand side, but we will be using one of the Deep Learning AMIs which are pre-configured with everything we need.
We want to select ‘Deep Learning AMI (Ubuntu)’:

As stated, this comes with some useful frameworks such as Keras and TensorFlow. Other settings for this configuration include EBS (Elastic Block Storage), which provides persistent storage for our instance, and HVM (Hardware Virtual Machine) virtualization which is fully virtualized rather than the lighter PV (Paravirtual). Other options such as Microsoft or Linux over Ubuntu are available if you would prefer.
At the next stage we will select the p2.xlarge instance:
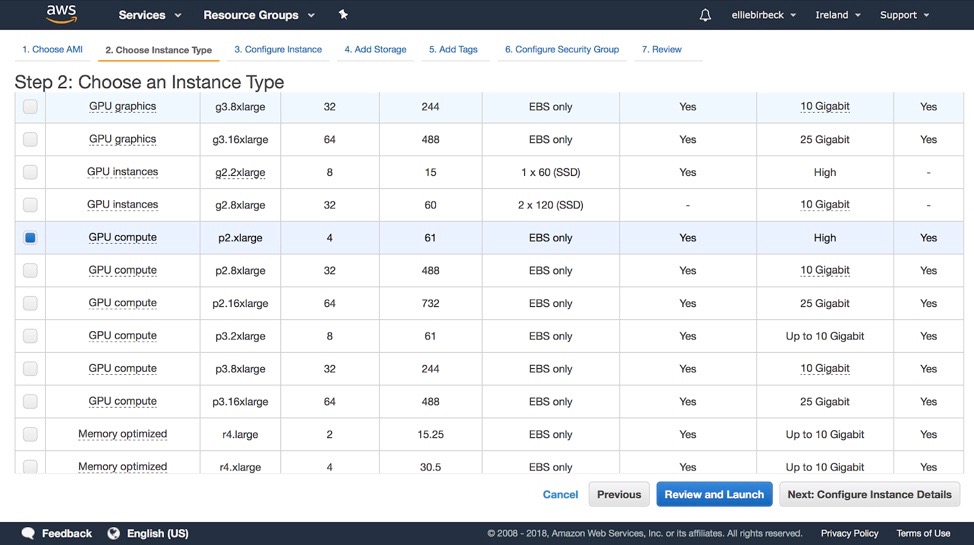
And then we are ready to ‘Review and Launch’.
SSH Key Pair
Once you have clicked the button to launch your instance, you should get a popup window prompting you to assign a key pair to the instance. This is referring to a public key stored with AWS and a private key stored on your personal machine, which we will now create. The key pair is used as a security measure, to authorise access to the instance.
Select ‘Create a new key pair’, and name it anything you like, such as ‘GPU-key’. Download the key and ensure it is saved with the file extension ‘.pem’.
Now we can go to the EC2 dashboard and view our instances by selecting ‘Running Instances’. Make a note of the Instance ID and Public DNS name displayed here. Initially the instance state will be displayed as ‘pending’, and after a short while it will update to ‘running’. Our instance is now ready to use!
Using Instance
Now let’s go to our back to our terminal and use the CLI to navigate to the directory where our private key is stored. For security, we will first make sure that the file permissions on our private key are actually private:
chmod 400 GPU-key.pem
And now we are ready to SSH into our running GPU instance:
ssh -i GPU-key.pem ubuntu@ec2-34-244-87-180.eu-west-1.compute.amazonaws.com
Make sure the .pem file for our key is the correct filename, and that the user_name@public_dns_name uses your own details. The username section will be ‘ubuntu’ if you followed our exact configuration and selected the Ubuntu AMI, but other options include ‘ec2-user’ for Linux, RHEL, and Fedora, or ‘centos’ for CentOS. The DNS name is what you should have noted earlier from the instance page.
Once executed, we should get an authenticity warning to which we can respond ‘yes’.
The terminal should now display a welcome entry:
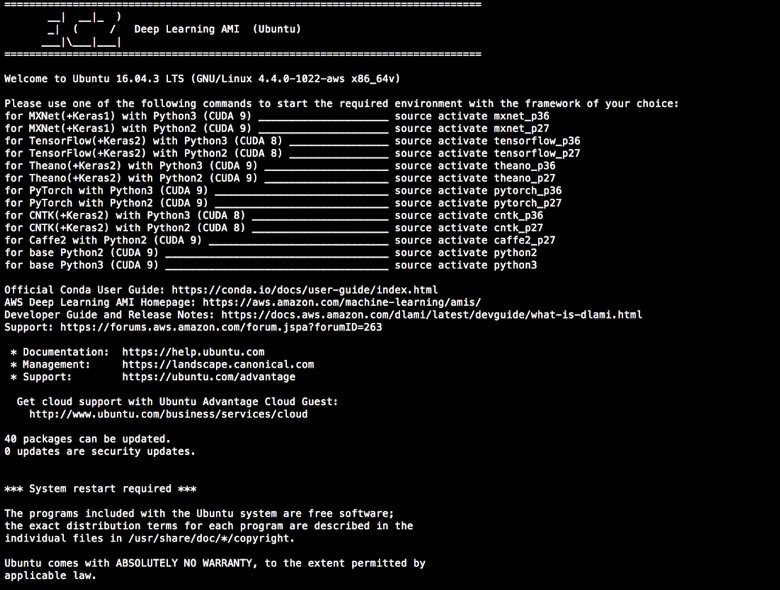
If you see:
*** System restart required ***
Then use:
sudo reboot
…to restart the system, and then SSH back in again.
Deep Learning
Now lets see how we can perform some tasks that would actually require the compute power of a GPU, such as deep learning. Here we will activate the specific environment we want to use, which for this example use case is the last option with Python 3.
source activate python3
We want to be able to run some code with a Jupyter notebook, so we first need to open a port for this on our instance’s firewall. From the EC2 dashboard scroll down to the ‘Network & Security’ section and click on ‘Security Groups’:
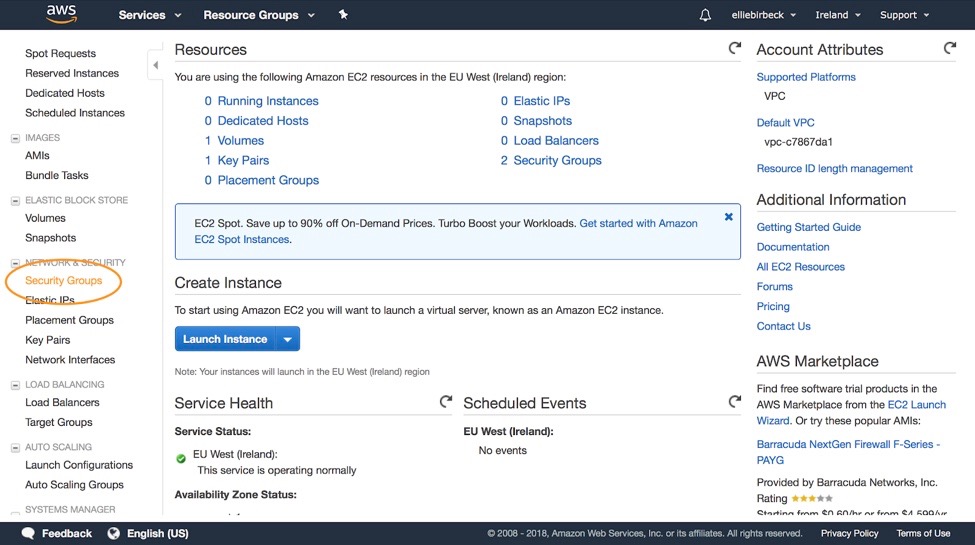
From the list of security groups, select the one with name ‘launch-wizard-1’, then click on the ‘Inbound’ tab, and the ‘Edit’ button:
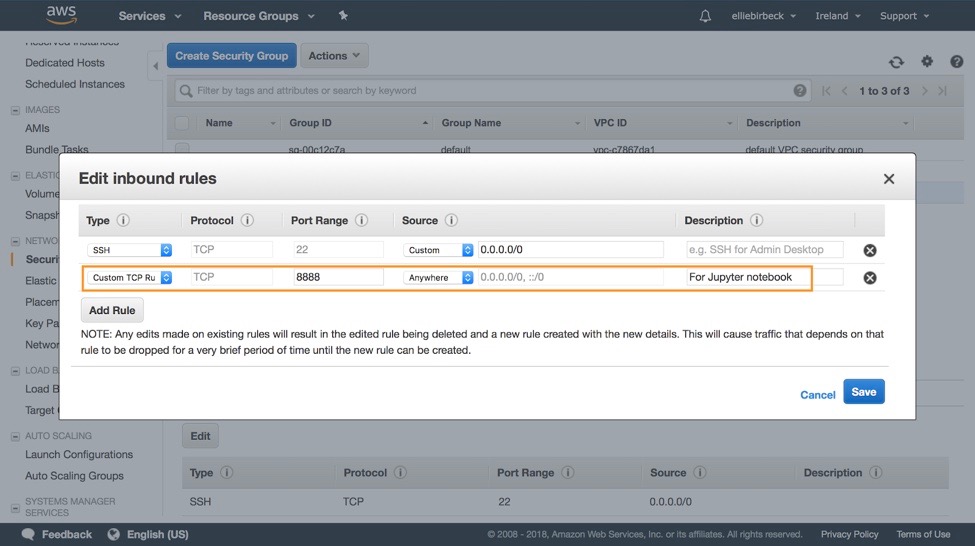
Here we want to add a new rule with the following specifications:
Next we will be configuring our Jupyter server by updating the config file and creating a Secure Sockets Layer (SSL) to establish an encrypted link between our server and the browser we will use to access the notebook.
Back in the terminal, execute the following commands (making sure we are still SSHed into the running instance):
mkdir ssl cd ssl sudo openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout "cert.key" -out "cert.pem" -batch
This generates an RSA private key and saves it to ‘cert.key’. Next we can create a password for logging into our Jupyter notebook server from the browser:
ipython from IPython.lib import passwd passwd() Enter password: your-password-here Verify password: your-password-here
We will be presented with a hash of our password similar to this:
'sha1:d148aca0…………………….'
Save this hash, and exit the iPython terminal (with the command ‘exit’).
Then open the config file and add the following to the end of the file:
c = get_config() c.NotebookApp.certfile = u'/home/ubuntu/ssl/cert.pem' c.NotebookApp.keyfile = u'/home/ubuntu/ssl/cert.key' c.IPKernelApp.pylab = 'inline' c.NotebookApp.ip = '*' c.NotebookApp.open_browser = False c.NotebookApp.password = 'sha1::d148aca0……………………..'
We are finally almost ready to start using our notebook. In the current terminal, lets get our notebook up and running:
jupyter notebook
And then in a separate terminal, we need to use the following command to forward all requests on a local port (8080, or any local unused port of our choice) to the port of our GPU instance (8888):
ssh -i GPU-key.pem -L 8080:127.0.0.1:8888 ubuntu@ec2-34-243-47-75.eu-west-1.compute.amazonaws.com
Now if we open up a browser and head to http://127.0.0.1:8080 we will see the Jupyter login page where we can use the password created earlier to securely gain access.
Once logged in, we are now ready to run some example code using the Jupyter notebook! If you are new to deep learning you can find some examples of projects to step through by clicking on the tutorials link, or you may have some of your own personal code that you would like to run on the GPU. But please note, doing anything time-consuming here will begin to charge your account. The fees are $0.90 per hour (pro-rata) for the exact configuration we used in this tutorial, but larger instances will cost more.
Here’s an example of the Hello TensorFlow tutorial available:
Analysing GPU performance
Once the GPU is put to use and some code is running, we can check up on its performance – determine which programs are executing, how much memory is being used etc. We will use the NVIDIA System Management Interface to take a look at these statistics.
In the CLI, run:
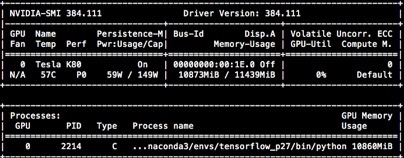
nvidia-smi
We are presented with an interface similar to the one below, which provides details such as whether the nvidia driver is running successfully, what processes are using the GPU, how much memory is being used, and the fan temperature, etc.
Increasing Compute Power
When more compute power is required, there are two approaches to consider. The first is referred to as ‘scaling up’ and involves upgrading to a larger, more powerful instance (the largest AWS currently offers is p2.16xlarge with 16 GPUs). The alternative approach of ‘scaling out’ involves creating a cluster of instances and distributing the workload among them. There are different advantages and disadvantages to each method. For example, 8 p2.xlarge instances and 1 p2.8xlarge instance provide the same compute power. With 8 instances running, the likelihood of an instance failing is higher than with 1 instance, however the impact of 1 failure out of 8 is much less than the impact of our 1 and only instance failing.
We will not step through the process of adding further instances or increasing our current instance in this tutorial, but doing so is as simple as repeating the steps taken so far. If you want to scale up, just select a more powerful instance, such as p2.8xlarge, when you are configuring the new instance. To scale out, just repeat our exact steps multiple times, creating new instances of the same configuration. In both cases, you will first need to request a further service limit increase.
Cloud Storage
AWS has a huge span of tools and services, but one other worth mentioning in relation to GPU usage is their storage service. Often if we are executing compute-heavy tasks such as deep learning, we may be reading to and writing from large stores of data. Our running instance already has some amount of storage (our configuration has 50GiB), but this lives and dies with the instance. We can copy files to and from our instance using two commands.
To transfer a file to our instance:
scp -i GPU-key.pem my-file.txt ubuntu@ec2-34-244-87-180.eu-west-1.compute.amazonaws.com:~
And back in the other direction, from the instance to our machine:
scp -i GPU-key.pem ubuntu@ec2-34-244-87-180.eu-west-1.compute.amazonaws.com:~/my-file.txt
But for a more persistent method, we can store data separately in the cloud, using Amazon’s Simple Storage Service (also known as S3). This storage system refers to uploaded objects as ‘buckets’. Here we can save an example csv file as a bucket called ‘mybucket’.
aws s3 cp my-file.csv s3://mybucket/
Storing our data separately from the instance means it is accessible from multiple instances (and other sources), and is still accessible when the instance is not running.
Shutting down
The final step (and perhaps the most important step) for this post is to shut down your instance. As the GPU instances incur hourly charges, we don’t want to accidentally leave one running overnight! You can set up billing alerts here if you are worried you might forget.
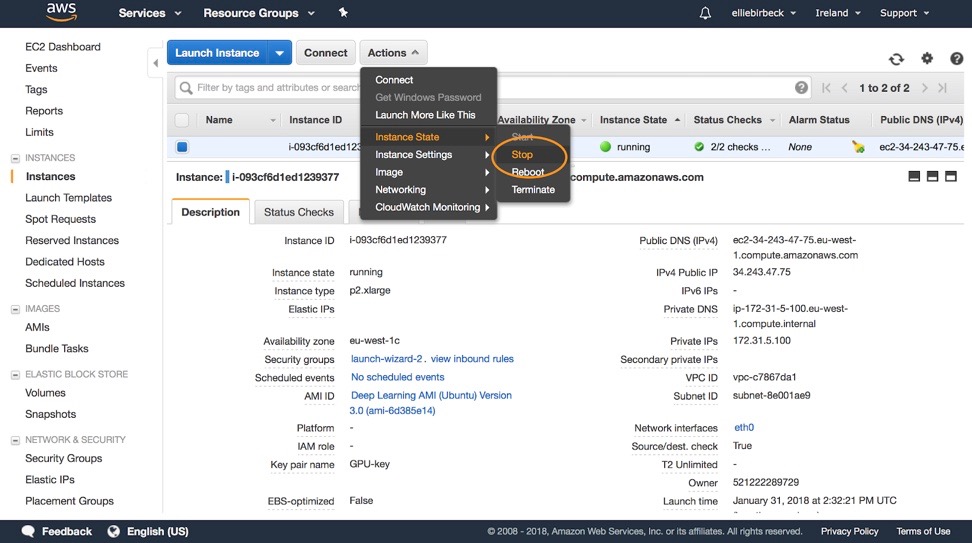
To shut down an instance head to the EC2 instances dashboard, select the instance, and then Actions > Instance State > Stop.
Conclusion
We have now successfully set up, launched, and shut down an instance of a GPU in the cloud, and can easily restart our configured instance any time we would like to access the accelerated compute power or resources it provides.
Deep learning is just one example of a task which may require such power, but many other compute-heavy tasks such as graphics rendering, or bitcoin mining, can be executed much more efficiently with this approach.
If you are interested in using the AWS cloud computing services for smaller-scale tasks that do not require a GPU, it is worth mentioning that other instances can be configured for free, using CPUs and with less memory and processing power.
